Accuracy Level
High
Enabled Analyses
Survey + Characterization (Trip Counts and FLOP with cache simulation and medium data transfer simulation) + Dependencies + Performance Modeling
Result Interpretation
Without the Dependencies analysis, if a loop is not explicitly marked as parallel with pragmas or if a compiler assumes dependencies present, Intel® Advisor assumes the loop is not recommended for offloading because they have high compute time. In this case, you can see high percentage of dependency-bound code regions. To get accurate information about dependencies, run the Dependencies analysis.
After running the Offload Modeling perspective with High accuracy, you will get a complete Offload Modeling report extended with detailed information about loops that have and do not have dependencies and a full data transfer report.
If you had a report generated for a lower accuracy, all offload recommendations, metrics, and speedup will be updated to be more precise taking into account new data.
Note
This topic describes data as it is shown in the Offload Modeling report in the Intel Advisor GUI and an interactive HTML report.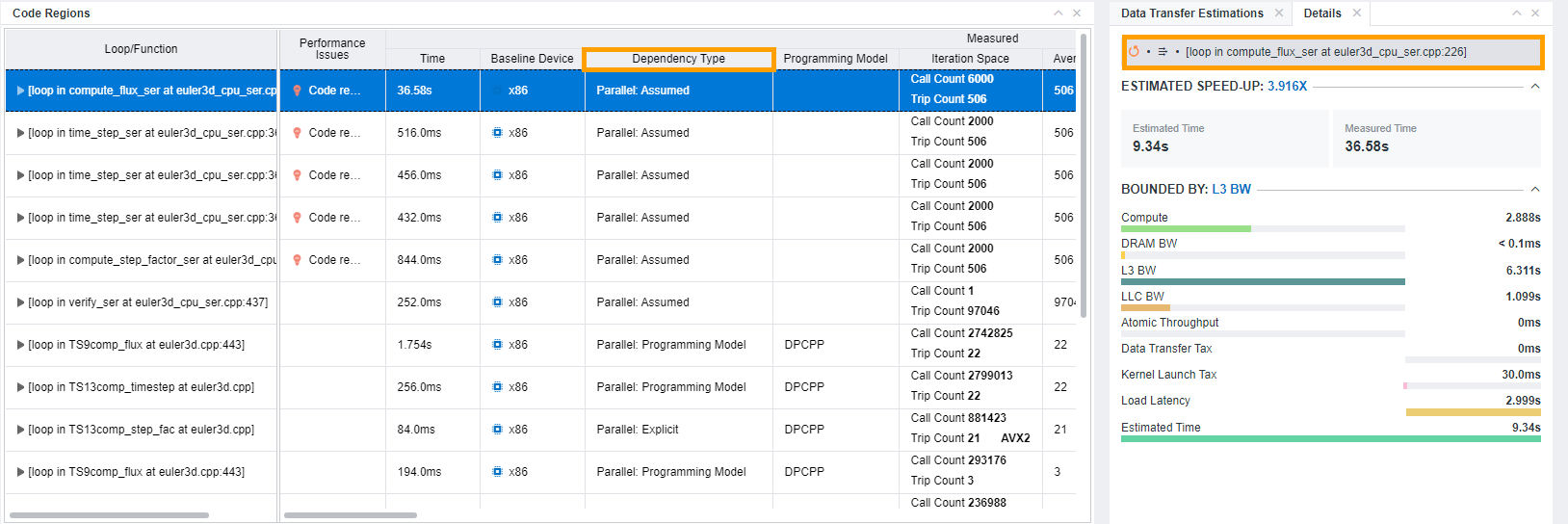
In the metrics table of the Accelerated Regions tab:
- Expand the
Measured column group and see the
Dependency Type column. It indicates if the loop has dependencies and if yes, reports dependency types.
In the Details tab, see an icon indicating loop dependency type:
 - code region is parallel or can be parallelized.
- code region is parallel or can be parallelized.
 - code region has dependencies.
- code region has dependencies.
- In the Throughput column of the Estimated Bound-by group, review time spent for dependencies-bound parts of your code. If the value is high, fix the dependencies.
- Intel Advisor might detect that some of the loops do not have dependencies and can be offload candidates, even though they were previously assumed as having dependencies. Review the list of loops/functions considered profitable for offloading for new candidates.
Review the Data Transfer Estimations pane with detailed information about data transferred between host and device and memory objects. In addition to basic data transfer report, it includes:
- Offloaded memory objects with size and transfer direction.
- The histogram distribution of objects that the selected region accessed by size.
Get guidance for offloading your code to a target device and optimizing it so that your code benefits the most in the Recommendations tab. If the code region has room for optimization or underutilizes the capacity of the target device, Intel Advisor provides you with hints and code snippets that may be helpful to you for further code improvement.
Next Steps
If you think that the estimated speedup is enough and the application is ready to be offloded, rewrite your code to offload profitable code regions to a target platform and measure performance of GPU kernels with GPU Roofline Insights perspective.