In addition to GPU pinning, the Intel MPI Library supports GPU buffers (see below).
GPU Pinning
Use this feature to distribute Intel GPU devices between MPI ranks.
To enable this feature, set I_MPI_OFFLOAD_TOPOLIB=level_zero. This feature requires that the Level-Zero* library be installed on the nodes. The device pinning information is printed out in the Intel MPI debug output at I_MPI_DEBUG=3.
Default settings:
I_MPI_OFFLOAD_CELL=tile
I_MPI_OFFLOAD_DOMAIN_SIZE=-1
I_MPI_OFFLOAD_DEVICES=all
By default, all available resources are distributed between MPI ranks as equally as possible given the position of the ranks; that is, the distribution of resources takes into account on which NUMA node the rank and the resource are located. Ideally, the rank will have resources only on the same NUMA node on which the rank is located.
Examples
All examples below represent a machine configuration with two NUMA nodes and two GPUs with two tiles.
Figure 1. Four MPI Ranks
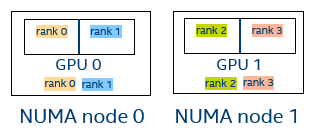
Debug output I_MPI_DEBUG=3:
[0] MPI startup(): ===== GPU pinning on host1 =====
[0] MPI startup(): Rank Pin tile
[0] MPI startup(): 0 {0}
[0] MPI startup(): 1 {1}
[0] MPI startup(): 2 {2}
[0] MPI startup(): 3 {3}
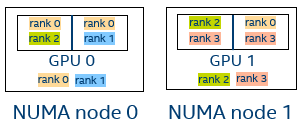
Figure 2. Three MPI Ranks
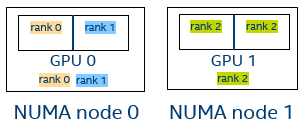
Debug output I_MPI_DEBUG=3:
[0] MPI startup(): ===== GPU pinning on host1 =====
[0] MPI startup(): Rank Pin tile
[0] MPI startup(): 0 {0}
[0] MPI startup(): 1 {1}
[0] MPI startup(): 2 {2,3}
I_MPI_OFFLOAD_TOPOLIB
Set the interface for GPU topology recognition.
Syntax
I_MPI_OFFLOAD_TOPOLIB=<arg>
Arguments
<arg> String parameter.
level_zero Use Level-Zero library for GPU topology recognition.
none Disable GPU recognition and GPU pinning.
Description
Set this environment variable to define the interface for GPU topology recognition. Setting this variable enables the GPU Pinning feature.
I_MPI_OFFLOAD_LEVEL_ZERO_LIBRARY
Specify the name and full path to the Level-Zero library.
Syntax
I_MPI_OFFLOAD_LEVEL_ZERO_LIBRARY="<path>/<name>"
Arguments
<path> Full path to the Level-Zero library.
<name> Name of the Level-Zero library.
Description
Set this environment variable to specify the name and full path to Level-Zero library. Set this variable if Level-Zero is not located in the default path. Default value: libze_loader.so.
I_MPI_OFFLOAD_CELL
Set this variable to define the base unit: tile (subdevice) or device (GPU).
Syntax
I_MPI_OFFLOAD_CELL=<cell>
Arguments
<cell> Specify the base unit.
tile One tile (subdevice). Default value.
device Whole device (GPU) with all subdevices
Description
Set this variable to define the base unit. This variable may affect other GPU pinning variables.
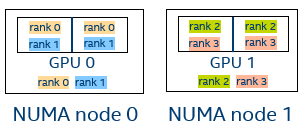
Example
Figure 3. Four MPI ranks, I_MPI_OFFLOAD_CELL=device
I_MPI_OFFLOAD_DOMAIN_SIZE
Control the number of base units per MPI rank.
Syntax
I_MPI_OFFLOAD_DOMAIN_SIZE=<value>
Arguments
<value> Integer number.
-1 Auto. Default value. Each MPI rank may have a different domain size to use all available resources.
> 0 Custom domain size.
Description
Set this variable to define how many base units will be pinned to the MPI rank. I_MPI_OFFLOAD_CELL variable defines the base unit: tile or device.
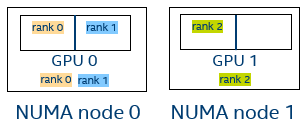
Examples
Figure 4. Three MPI ranks, I_MPI_OFFLOAD_DOMAIN_SIZE=1
I_MPI_OFFLOAD_DEVICES
Define a list of available devices.
Syntax
I_MPI_OFFLOAD_DEVICES=<devicelist>
Arguments
<devicelist> A comma-separated list of available devices.
all All devices are available. Default value.
<l> Device with logical number <l>.
<l>-<m> Range of devices with logical numbers from <l> to <m>.
<k>,<l>-<> Device <k> and devices from <l> to <m>.
Description
Set this variable to define the available devices. This variable also gives you the ability to exclude devices.
Example
Figure 5. Four MPI ranks, I_MPI_OFFLOAD_DEVICES=0
I_MPI_OFFLOAD_DEVICE_LIST
Define a list of base units to pin for each MPI rank.
Syntax
I_MPI_OFFLOAD_DEVICE_LIST=<base_units_list>
Arguments
<base_units_list> A comma-separated list of base units. The process with the i-th rank is pinned to the i-th base unit in the list.
<l> Base unit with logical number <l>.
<l>-<m> Range of base units with logical numbers from <l> to <m>.
<k>,<l>-<m> Base unit <k> and base units from <l> to <m>.
Description
Set this variable to define the list of base units to pin for each MPI rank. The process with the i-th rank is pinned to the i-th base unit in the list.
I_MPI_OFFLOAD_CELL variable defines the base unit: tile or device.
I_MPI_OFFLOAD_DEVICE_LIST variable has less priority than the I_MPI_OFFLOAD_DOMAIN variable.
Example
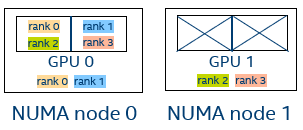
Figure 6. Four MPI ranks, I_MPI_OFFLOAD_DEVICE_LIST=3,2,0,1
I_MPI_OFFLOAD_DOMAIN
Define domains through the comma separated list of hexadecimal numbers for each MPI rank.
Syntax
I_MPI_OFFLOAD_DOMAIN=<masklist>
Arguments
<masklist> A comma-separated list of hexadecimal numbers.
[m1,...,mn ] For <masklist>, each mi is a hexadecimal bit mask defining an individual domain.
The following rule is used: the i-th base unit is included into the domain if the corresponding bit in mi value is set to 1.
Description
Set this variable to define the list of hexadecimal bit masks. For the i-th bit mask, if the j-th bit set to 1, then the j-th base unit will be pinned to the i-th MPI rank.
I_MPI_OFFLOAD_CELL variable defines the base unit: tile or device.
I_MPI_OFFLOAD_DOMAIN variable has higher priority than the I_MPI_OFFLOAD_DEVICE_LIST.
Example
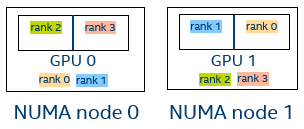
Figure 7. Four MPI ranks, I_MPI_OFFLOAD_DOMAIN=[B,2,5,C]. Parsed bit masks: [1101,0100,1010,0011]
GPU Buffers Support
I_MPI_OFFLOAD
Syntax
I_MPI_OFFLOAD=<value>
Arguments
| Value | Integer Number |
|---|---|
| 0 | Disabled (default value) |
| 1 | Auto. Intel MPI expects that libze_loader.so is already loaded and does not load it twice |
| 2 | Enabled. Intel MPI loads libze_loader.so |
Description
Set this variable to enable handling of device buffers in MPI functions such as MPI_Send, MPI_Recv, MPI_Bcast, MPI_Allreduce, and so on by using the Level Zero library specified in the I_MPI_OFFLOAD_LEVEL_ZERO_LIBRARY variable.
In order to pass a pointer of an offloaded memory region to MPI, you may need to use specific compiler directives or get it from corresponding acceleration runtime API. For example, use_device_ptr and use_device_addr are useful keywords to obtain device pointers in the OpenMP environment, as shown in the following code sample:
/* Copy data from host to device */
#pragma omp target data map(to: rank, values[0:num_values]) use_device_ptr(values)
{
/* Compute something on device */
#pragma omp target parallel for is_device_ptr(values)
for (unsigned i = 0; i < num_values; ++i) {
values[i] *= (rank + 1);
}
/* Send device buffer to another rank */
MPI_Send(values, num_values, MPI_INT, dest_rank, tag, MPI_COMM_WORLD);
}
I_MPI_OFFLOAD_MEMCPY
Set this environment variable to select the GPU memcpy kind
Syntax
I_MPI_OFFLOAD_MEMCPY=<value>
Arguments
<value> Description
cached Cache created objects for communication with GPU so that they can be reused if the same device buffer is later provided to the MPI function. Default value.
blocked Copy device buffer to host and wait for the copy to be completed inside MPI function.
nonblocked Copy device buffer to host and do not wait for the copy to be completed inside MPI function. Wait for the operation completion in MPI_Wait.
Description
Set this environment variable to select the GPU memcpy kind. The best performed option is chosen by default. Nonblocked memcpy can be used with MPI non-blocked point-to-point operations to achieve the overlap with compute part. Blocked memcpy can be used if other types are not stable.
I_MPI_OFFLOAD_PIPLINE
Set this environment variable to enable pipeline algorithm.
Syntax
I_MPI_OFFLOAD_PIPELINE=<value>
Arguments
<value> Description
1 Enable pipeline algorithm. Default value.
0 Disable pipeline algorithm.
Description
Set this environment variable to enable pipeline algorithm, which can improve performance for large message sizes. The main idea of the algorithm is to split user buffer into several segment, and copy the segments to the host and send them to another rank.
I_MPI_OFFLOAD_PIPLINE_THRESHOLD
Set this environment variable to control the threshold for pipeline algorithm.
Syntax
I_MPI_OFFLOAD_PIPELINE_THRESHOLD=<value>
Arguments
<value> Description
>0 Threshold in bytes. The default value is 524288
Description
This variable controls the message size from which the pipeline algorithm is used.