You can use one of the following approaches to image warping:
Interpolation algorithms of the Nearest Neighbor, Linear, and Cubic types can use edge pixels of the source image that are out of the image origin. When calling the ippiWarpAffine<Filter> function with one of these interpolation algorithms applied, you need to specify the appropriate border type. The following border types are supported:
- Replicated borders: border pixels are replicated from the source image boundary pixels
- Constant border: values of all border pixels are set to a constant
- Transparent borders: destination pixels that have inverse transformed location out of the source image are not processed
- Borders in memory: the source image border pixels are obtained from the source image pixels in memory
- Mixed borders: combination of transparent borders and borders in memory is applied
Warping the Whole Image
You can follow the approach described below to apply affine transformation when source and destination images are fully accessible in memory. However, this method only runs on a single thread.
To transform the whole image:
- Call the WarpAffineGetSize function with the appropriate interpolation type. This function uses source and destination image sizes to calculate how much memory must be allocated for the IppWarpSpec structure and work buffer.
- Initialize the IppWarpSpec structure by calling the ippiWarp<Filter>Init, where <Filter> can take one of the following values: Nearest, Linear, and Cubic. These prerequisite steps enable calling the warp functions multiple times without recalculations.
- Call the WarpGetBufferSize function for the initialized IppWarpSpec structure. This function uses the destination image size to calculate how much memory must be allocated for the warp work buffer.
- Call ippiWarpAffine<Filter> with the appropriate image type.
- Specify the algorithm for borders processing by setting the
borderType and
pBorderValue parameters when initializing the
IppiWarpSpec structure. The data type of
pBorderValue is automatically converted from
Ipp64f to the data type of the processed images. The function supports the following algorithms for borders processing:
If the border type is equal to ippBorderRepl, the source image outer pixels are replicated from the edge pixels.
If the border type is equal to ippBorderConst, the outer pixels are set to the constant value specified in pBorderValue.
If the border type is equal to ippBorderTransp, destination image pixels mapped to the outer source image pixels are not changed. The outer pixels are replicated from the edge pixels, if they are required by interpolation algorithm.
If the border type is equal to ippBorderInMem, destination image pixels mapped to the outer source image pixels are not changed. The outer pixels are obtained from the out of of the source image origin space, if they are required by interpolation algorithm.
The mixed border types can be obtained by the bitwise operation OR between ippBorderTransp and the ippBorderInMemTop, ippBorderInMemBottom, ippBorderInMemLeft, ippBorderInMemRight values.
Figure Whole Image Warping shows a simple image affine transformation example. Transformation coefficients are {{1.0, 0.5, 0.0}, {0.5, 1.0, 0.0}}, border type is ippBorderConst, pBorderValue is a white color pixel. The size of the destination image is 1.2x of the source image size.

Example
The code example below demonstrates affine transformation of the whole image with the linear interpolation method:
IppStatus warpAffineExample_8u_C3R(Ipp8u* pSrc, IppiSize srcSize, Ipp32s srcStep, Ipp8u* pDst, IppiSize dstSize,
Ipp32s dstStep, const double coeffs[2][3])
{
IppiWarpSpec* pSpec = 0;
int specSize = 0, initSize = 0, bufSize = 0; Ipp8u* pBuffer = 0;
const Ipp32u numChannels = 3;
IppiPoint dstOffset = {0, 0};
IppStatus status = ippStsNoErr;
IppiBorderType borderType = ippBorderConst;
IppiWarpDirection direction = ippWarpForward;
Ipp64f pBorderValue[numChannels];
for (int i = 0; i < numChannels; ++i) pBorderValue[i] = 255.0;
/* Spec and init buffer sizes */
status = ippiWarpAffineGetSize(srcSize, dstSize, ipp8u, coeffs, ippLinear, direction, borderType, &specSize, &initSize);
if (status != ippStsNoErr) return status;
/* Memory allocation */
pSpec = (IppiWarpSpec*)ippsMalloc_8u(specSize);
if (pSpec == NULL)
{
return ippStsNoMemErr;
}
/* Filter initialization */
status = ippiWarpAffineLinearInit(srcSize, dstSize, ipp8u, coeffs, direction, numChannels, borderType, pBorderValue, 0, pSpec);
if (status != ippStsNoErr)
{
ippsFree(pSpec);
return status;
}
/* work buffer size */
status = ippiWarpGetBufferSize(pSpec, dstSize, &bufSize);
if (status != ippStsNoErr)
{
ippsFree(pSpec);
return status;
}
pBuffer = ippsMalloc_8u(bufSize);
if (pBuffer == NULL)
{
ippsFree(pSpec);
return ippStsNoMemErr;
}
/* Resize processing */
status = ippiWarpAffineLinear_8u_C3R(pSrc, srcStep, pDst, dstStep, dstOffset, dstSize, pSpec, pBuffer);
ippsFree(pSpec);
ippsFree(pBuffer);
return status;
}Warping a Tiled Image with One Prior Initialization
You can follow the approach described below to apply affine transformation when the source image is fully accessible in memory and destination image is not fully accessible in memory, or to improve performance of warping by external threading.
The main difference between this approach and whole image warping is that the image is split into sections called tiles. Each call of the WarpAffine<Filter> function works with the destination image origin region of interest (ROI) that is defined by dstRoiOffset and dstRoiSize parameters. The destination ROI must be fully accessible in memory.
To resize an image with the tiled approach:
- Call the WarpAffineGetSize function with the appropriate interpolation type. This function uses the size of the source and destination images and transformation parameters to calculate how much memory must be allocated for the IppWarpSpec structure and initialization work buffer.
- Initialize the IppWarpSpec structure by calling ippiWarpAffine<Filter>Init, where <Filter> can take one of the following values: Nearest, Linear, and Cubic.
- Determine an appropriate partitioning scheme to divide the destination image into tiles. Tiles can be sets of rows or a regular grid of subimages. A simple vertical subdivision into sets of lines is sufficient in most cases.
- Call the WarpGetBufferSize function to obtain the size of the work buffer required for each tile processing. The dstRoiSize parameter must be equal to the tile size.
- Call
ippiWarpAffine<Filter> for each tile (ROI). The
dstRoiOffset parameter must specify the image ROI offset with respect to the destination image origin. The
dstRoiSize parameter must be equal to the ROI size. The
pDst parameter must point to the beginning of the destination ROI in memory. The source and destination ROIs must be fully accessible in memory.
You can process tiles in any order. When using multiple threads you can process all tiles simultaneously.
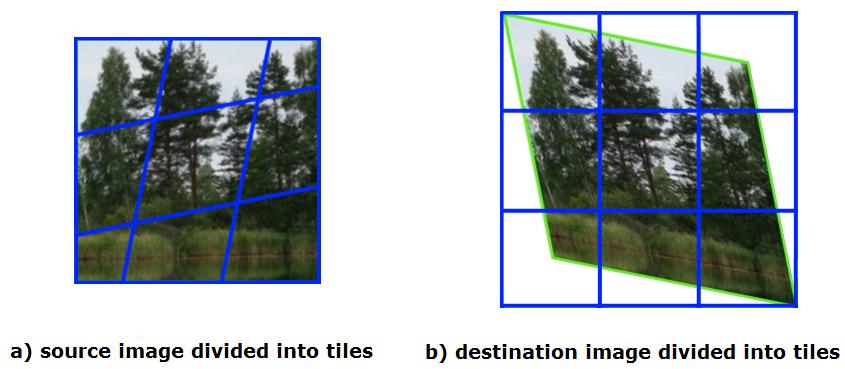
Figure Tiled Image Warping shows the affine transformation of the image divided into tiles. Transformation coefficients are {{1.0, 0.5, 0.0}, {0.5, 1.0, 0.0}}, applied border type is ippBorderConst, pBorderValue is a white color pixel. The size of the destination image is 1.2x of the source image size.
Example
The code example below demonstrates a multithreading affine transformation using OpenMP* with parallelization only in y direction:
IppStatus tileWarpAffineExample_C3R(Ipp8u* pSrc, IppiSize srcSize, Ipp32s srcStep, Ipp8u* pDst, IppiSize dstSize, Ipp32s dstStep, const double coeffs[2][3])
{
IppiWarpSpec* pSpec = 0;
int specSize = 0, initSize = 0, bufSize = 0; Ipp8u* pBuffer = 0;
Ipp8u* pInitBuf = 0;
const Ipp32u numChannels = 3;
IppiPoint dstOffset = {0, 0};
IppiPoint srcOffset = {0, 0};
IppStatus status = ippStsNoErr;
IppiBorderType borderType = ippBorderConst;
IppiWarpDirection direction = ippWarpForward;
int numThreads, slice, tail;
int bufSize1, bufSize2;
IppiSize dstTileSize, dstLastTileSize; IppStatus pStatus[MAX_NUM_THREADS];
Ipp64f pBorderValue[numChannels];
for (int i = 0; i < numChannels; ++i) pBorderValue[i] = 255.0;
/* Spec and init buffer sizes */
status = ippiWarpAffineGetSize(srcSize, dstSize, ipp8u, coeffs, ippLinear, direction, borderType, &specSize, &initSize);
if (status != ippStsNoErr) return status;
/* Memory allocation */
pSpec = (IppiWarpSpec*)ippsMalloc_8u(specSize);
if (pSpec == NULL)
{
return ippStsNoMemErr;
}
/* Filter initialization */
status = ippiWarpAffineLinearInit(srcSize, dstSize, ipp8u, coeffs, direction, numChannels, borderType, pBorderValue, 0, pSpec);
if (status != ippStsNoErr)
{
ippsFree(pSpec);
return status;
}
/* General transform function */
/* Parallelized only by Y-direction here */
#pragma omp parallel num_threads(MAX_NUM_THREADS)
{
#pragma omp master
{
numThreads = omp_get_num_threads();
slice = dstSize.height / numThreads; tail = dstSize.height % numThreads;
dstTileSize.width = dstLastTileSize.width = dstSize.width;
dstTileSize.height = slice;
dstLastTileSize.height = slice + tail;
ippiWarpGetBufferSize(pSpec, dstTileSize, &bufSize1);
ippiWarpGetBufferSize(pSpec, dstLastTileSize, &bufSize2);
pBuffer = ippsMalloc_8u(bufSize1 * (numThreads - 1) + bufSize2);
}
#pragma omp barrier
{
if (pBuffer)
{
Ipp32u i;
Ipp8u *pDstT; Ipp8u *pOneBuf;
IppiPoint srcOffset = {0, 0};
IppiPoint dstOffset = {0, 0};
IppiSize srcSizeT = srcSize; IppiSize dstSizeT = dstTileSize;
i = omp_get_thread_num();
dstSizeT.height = slice; dstOffset.y += i * slice;
if (i == numThreads - 1) dstSizeT = dstLastTileSize;
pDstT = (Ipp8u*)((char*)pDst + dstOffset.y * dstStep);
pOneBuf = pBuffer + i * bufSize1;
pStatus[i] = ippiWarpAffineLinear_8u_C3R (pSrc, srcStep, pDstT, dstStep, dstOffset, dstSizeT, pSpec, pOneBuf);
}
}
}
ippsFree(pSpec);
if (pBuffer == NULL) return ippStsNoMemErr;
ippsFree(pBuffer);
for (Ipp32u i = 0; i < numThreads; ++i)
{
/* Return bad status */
if(pStatus[i] != ippStsNoErr) return pStatus[i];
}
return status;
}