This section provides the syntax and semantics for the C/C++ language extensions for array notations.
Array Section Notation
In your application code, introduce a section operator in the standard C/C++ language, as follows:
section_operator ::= [<lower bound> : <length> : <stride>]
where the <lower bound>, <length>, and <stride> are of integer types, representing a set of integer values as follows:<lower bound>, <lower bound + <stride>>, …, <lower bound> + (<length> - 1) * <stride>
A section operator can occur in place of a subscript operator. The following example is an array section with len elements: a[lb], a[lb + str], a[lb + 2*str], …, a[lb + (len-1)*str].a[lb:len:str]
Length is chosen instead of upper bound because, in declarations, C/C++ deals with lengths of arrays and not upper bounds. Use of length also makes it easier to ensure that array sections match in size.
Successive section operators designate a sub-array of a multidimensional array object. When absent, the <stride> defaults to 1. If the <length> is less than 1, the array section is undefined. You can also use [:] as a short hand for a whole array dimension if the size of the dimension is known from the array declaration. If either <lower bound> or <length> must be specified, you must specify both.
Array Declarations for Array Notations
For the array section notation to be useful, the compiler must know the shape and size of an array object. The table below summarizes the different ways of declaring arrays and pointers to array objects in C/C++.
| Length | Storage Class | Declaration |
|---|---|---|
| Fixed | Static | static int a[16][128] |
| Auto | void foo(void) { int a[16][128]; } |
|
| Parameter | void bar(int a[16][128]); | |
| Heap | int (*p2d)[128]; | |
| Variable (C99) | Auto | void foo(int m, int n) { int a[m][n]; } |
| Parameter | void bar(int m, int n, int a[m][n]); | |
| Heap | void bar(int m, int n) { int (*p2d)[n]; } |
The variable length array (VLA) notation is a C99 [ISO/IEC 9899] extension. It is supported by the GNU GCC and Intel® compilers.
 Note
Note
You must use –std=c99 (Linux* and Mac OS* X) or /Qstd=c99 (Windows*) compiler option for the compiler to accept the C99 extensions.
If the base of an array section has incompletely specified dimensions (such as a pointer variable), you must explicitly specify the length of the array section. This is illustrated in the following example.
Operator Maps
Most C/C++ operators are available for array sections: +, -, *, /, %, <, ==, >, <=, !=, >=, ++, --, |, &, ^, &&, ||, !, -(unary), +(unary), +=, -=, *=, /=, *(pointer de-referencing). Operators are implicitly mapped to all elements of the array section operands. The operations on different elements can be executed in parallel with-out any ordering constraints.
Array operands in an operation must have the same rank and size. Rank is defined as the number of array section operators, and size is the length of each array section. A scalar operand is automatically filled to the whole array section of any rank.
Assignment Maps
The assignment operator applies in parallel to every element of the array section on the left hand side (LHS).
| Example |
|---|
a[:][:] = b[:][2][:] + c; e[:] = d; e[:] = b[:][1][:]; // error, different rank a[:][:] = e[:]; // error, different rank |
If there is an overlap between the RHS and the LHS, the behavior is undefined. There is no guarantee that the RHS will be evaluated before assignment to the LHS. If there is aliasing between the LHS and the RHS, the programmer must introduce a temporary array section to evaluate the RHS before assigning to the LHS. One exception is when there is an exact overlap and the stride is the same, then the assignment is well defined. This semantic allows for the most efficient code to be generated.
| Example |
|---|
a[1:s] = a[0:s] + 1; // due to overlap the behavior is undefined temp[0:s] = a[0:s] +1; // introduce temporary section to resolve a[1:s] = temp[0:s]; // the aliasing a[:] += b[:]; // This is well defined as there is exact overlap and stride 1 // a[:] = a[:] + b[:]; |
Gather and Scatter
When an array section occurs directly under a subscript expression, it designates a set of elements indexed by the values of the array section.
| Example |
|---|
unsigned index[10] = {0,1,2,3,4,5,6,7,8,9};
float out[10], in[10] = {9,8,7,6,5,4,3,2,1,0};
out[0:5] = in[index[0:5]]; // gather out[index[5:5]] = in[0:5]; //scatter for(int i = 0; i < 5; i++){
cerr << "out[" << i << "]" << out[i] << endl; } |
If the index values in a scatter array section overlap with each other, the values for the duplicated locations must be the same, otherwise, the final stored value after the scatter is undefined.
Depending on the target architecture option chosen, and if the scatter/gather support is available on the target architecture, the compiler may map the array notations operations to the appropriate hardware.
Reduction Operations
A reduction combines array section elements to generate a scalar result. Intel® Cilk™ Plus supports reductions on array sections. It defines a generic reduction function that applies a user-defined dyadic function and a generic mutating reduction function that applies the result of the reduction function. Intel® Cilk™ Plus also has nine built-in common reduction functions. The built-in functions are polymorphic functions that accept int, float, and other C basic data type arguments. The names and descriptions of reduction functions are summarized in the table below followed by details and examples.
| Function Prototypes | Descriptions |
|---|---|
| __sec_reduce(fun, identity, a[:]) | Generic reduction function. Reduces fun across the array a[:] using identity as the initial value. Deprecated. |
| result __sec_reduce(initial, a[:], function-id) | Generic reduction function that supports scalar types as well as C++ arithmetic classes. Performs a reduction operation across array, a[:], using the reduction function, function-id, with initial as the initial value. Returns the result of the reduction in result. |
| void __sec_reduce_mutating(reduction, a[:], function-id) | Generic mutating reduction function that supports scalar types as well as C++ arithmetic classes. Performs reduction operation across array, a[:], using the mutating reduction function, function-id, with the result of the reducing operation, reduction, accumulated in the initial value. Returns nothing. |
| Built-in Reduction Functions | |
| __sec_reduce_add(a[:]) | Adds values passed as arrays. |
| __sec_reduce_mul(a[:]) | Multiplies values passed as arrays. |
| __sec_reduce_all_zero(a[:]) | Tests that array elements are all zero. |
| __sec_reduce_all_nonzero(a[:]) | Tests that array elements are all non-zero. |
| __sec_reduce_any_nonzero(a[:]) | Tests for any array element that is non-zero. |
| __sec_reduce_min(a[:]) | Determines the minimum value of array elements. |
| __sec_reduce_max(a[:]) | Determines the maximum value of array elements. |
| __sec_reduce_min_ind(a[:]) | Determines the index of minimum value of array elements. |
| __sec_reduce_max_ind(a[:]) | Determines the index of maximum value of array elements. |
Generic reducing function: the function denoted by function-id can be a user-defined function, operator, functor, or lambda expression that require assignment on top of the operation, for example, operator+. The reduction function must be commutative. The element type of the array section is used for:
lookup and overload resolution of the reduction function
the assignment operator needed to assign the return value to the result
the copy constructor for the initial value to be assigned to the reduction variable used (if needed).
Note
The implementation allows for non-constant function pointers as the reduction function. Also, The returning reduction function can replace the original defined __sec_reduce(fun, identity, a[:]); reduction function with your user-defined function. The original defined reduction function is deprecated.
| Example |
|---|
... complex<double> a[N]; complex<double> result; ... result = __sec_reduce(complex<double>(0,0), a[:], operator+ ); ... |
Generic mutating reduction function: the function denoted by function-id can be a user-defined function, operator, functor, or lambda expression that requires assignment on top of the operation, for example, compound assignment operator+=. The reduction function must be commutative. The element type of the array section is used for lookup and overload resolution for the compound reduction function.
Note
An assignment operator is not needed for the mutating reduction case.
| Example |
|---|
... complex<double> a[N]; complex<double> result; ... result = complex<double>(0,0); __sec_reduce_mutating(result, a[:], operator+= ); ... |
Built-in reduction functions: the reduction operation can reduce on multiple ranks. The number of ranks reduced depends on the execution context. For a given execution context of rank m and a reduction array section argument with rank n, where n>m, the last n-m ranks of the array section argument are reduced.
Shift Operations
A shift does a shift of the elements in the array section elements to generate a scalar result. Intel® Cilk™ Plus supports shift operations on array sections. The names and descriptions of shift functions are summarized in the table below. The shift and circular shift (rotate) functions are defined for rank one expressions.
| Function Prototypes | Descriptions |
|---|---|
| b[:] = __sec_shift(a[:], signed shift_val, fill_val) | Generic shift function. Performs a shift operation on the elements of the array a[:] towards a higher/lower index value. A positive shift_val shifts towards lower index values while a negative shift_val shifts towards higher index values. The fill_val argument indicates the fill value of the array section element type that is used to fill the vacated elements. The result is assigned to the return value, b[:]. The array section argument, a[:] is not modified. |
| b[:] = __sec_rotate(a[:], signed shift_val) | Generic rotate function. Performs a circular shift (rotate) of the elements in the array section, a[:]. A positive shift_val rotates towards lower index values while a negative shift_val rotates towards higher index values. The result is assigned to the return value, b[:]. The array section argument a[:] is not modified. |
Function Maps
Maps are implicitly defined on scalar functions. All the array section arguments in a scalar function map call must have the same rank. Scalar arguments are automatically filled to match any rank.
| Example |
|---|
a[:] = sin(b[:]); a[:] = pow(b[:], c); // b[:]**c a[:] = pow(c, b[:]); // c**b[:] a[:] = foo(b[:]); // user defined function a[:] = bar(b[:], c[:][:]); //error, different ranks |
Mapped function calls are executed in parallel for all the array elements, with no specific ordering. Vector functions may have side effects. When there are conflicts during parallel execution, the program semantics may be different from the serial program.
Function maps are powerful tools used to apply a set of operations in parallel to all elements of an array section.
Many routines in the svml library are more highly optimized for Intel® microprocessors than for non- Intel microprocessors.
Passing Array Section Arguments
Intel® Cilk™ Plus supports a vector kernel style of programming, where vector code is encapsulated within a function by declaring array parameters of fixed or parameterized vector lengths.
The address of the first element of an array section can be passed as argument to an array parameter. The following example illustrates how to combine array notation to achieve vectorization inside a function body using Intel® Cilk™ Plus threading for parallel function calls.
Note
The parameter float x[m] depending on an earlier parameter int m is only supported in C99 and not in C++.
| Example |
|---|
#include <cilk/cilk.h> void saxpy_vec(int m, float a, float x[m], float y[m]){y[:]+=a*x[:]; } void main(void){int a[2048], b[2048] ; cilk_for (int i = 0; i < 2048; i +=256){saxpy_vec(256, 2.0, &a[i], &b[i]); } } |
By writing the function explicitly with array arguments, you can write portable vector codes using any threading runtime and scheduler.
Limitations
There are two limitations on the usage of array sections:
- Array sections cannot occur inside the conditional test of an if statement.
- The function cannot return array section values.
More often than not you can convert an if statement into a C/C++ conditional select operation in order to use array sections as shown in the following example.
| Example |
|---|
for (int i = 0; i < n; i++){ if (a[i] > b[i]){c[i] = a[i] - b[i]; } else{d[i] = b[i] - a[i]; } } //can be rewritten as c[0:n] = (a[0:n] > b[0:n]) ? a[0:n] - b[0:n] : c[0:n]; d[0:n] = (a[0:n] <= b[0:n]) ? b[0:n] - a[0:n] : d[0:n]; |
You can also pass a return array pointer argument to a function to achieve the same effect as a function return array value.
Programming Hints and Examples
There is no cost associated with writing an application that mixes scalar and data parallel operations on the same arrays. The Intel® compiler uses the array operations in the program to guide vectorization. The following example implements an FIR filter. The scalar code consists of a doubly nested loop where both the inner and outer loop can be vectorized. By writing the program in different ways using array notation, you can direct the compiler to vectorize differently.
| Example: FIR Scalar Code |
|---|
for (i=0; i<M-K; i++){s = 0 for (j=0; j<K; j++){s+= x[i+j] * c[j]; } y[i] = s; } |
| Example: FIR Inner Loop Vector |
for (i=0; i<M-K; i++){y[i] = __sec_reduce_add(x[i:K] * c[0:K]); } |
| Example: FIR Outer Loop Vector |
y[0:M-K] = 0; for (j=0; j<K; j++){y[0:M-K]+= x[j:M-K] * c[j]; } |
The parallel array assignment semantics enables vectorization of computations on the right hand side (RHS) of the assignment even if the l-value of the assignment may alias with some operands on the RHS. The compiler introduces temporary arrays when aliasing occurs. Temporary arrays increase memory usage and incur extra overhead of writing and reading them. You can help eliminate unnecessary temporary copying by providing better aliasing information such as C99 restrict pointer attribute as shown in the following example:
| Example: Using C99 restrict Pointer [no overlapping assignments] |
|---|
void saxpy_vec(int m, float a, float (&x)[m], float(&y)[m]){y[:] += a * x[:]; // x may overlap with y, // temporary array t[n] allocated by the compiler // t[:] = y[:] + a * x[:]; y[:] = t[:] } void saxpy_vec(int m, float a, float *restrict x, float(&y)[m]){y[:] += a * x[0:m]; // x and y are disjointed, no temporary array } |
Since the behavior is undefined for overlapping assignments and the compiler does not introduce temporary array sections to resolve the dependencies, the compiler generates efficient code even when there is a possibility for overlap.
| Example: Using C99 restrict Pointer [overlapping assignments] |
|---|
void saxpy_vec(int m, float a, float (&x)[m], float(&y)[m]){y[:] += a * x[:]; // x may overlap with y, but no temp array allocated } // code is vectorized as efficiently as if the restrict keyword is used void saxpy_vec(int m, float a, float restrict *x, float(&y)[m]){y[:] += a * x[0:m]; // x and y are disjoint } |
To take full advantage of vector instruction set, it is often beneficial to use a fixed vector length supported by the processor, as illustrated in the next example. The example code computes an average over nine points in a two-dimensional grid (avoiding the 1-element boundary around the grid where the nine-point average is not defined). The core computation is written in vector form as in a function nine_point_average. The application is further parallelized using a cilk_for loop at the call site. The grain size of the computation is controlled by the two compile time constants, VLEN and NROWS, which designate the length of vector operations and the number of rows processed in each invocation. Because the loads of adjacent rows are reused across multiple rows, you gain on memory locality by processing multiple rows inside the function. Using compile time constant for vector length makes the vector code generation more efficient and predictable.
| Example |
|---|
#include <malloc.h> #include <cilk/cilk.h> #define VLEN 4 #define NROWS 4 //------------------------------------------------------------------- // Vector kernel // for each grid // o[x][y] = (i[x-1][y-1] + i[x-1][y]+ i[x-1][y+1] + // i[x][y-1] + i[x][y] + i[x][y+1] + // i[x+1][y-1] + i[x+1][y] + i[x+1][y+1])/9; // written with: // 1) VLEN columns for vectorization // 2) NROWS rows for the reuse of the adjacent row loads //-------------------------------------------------------------------- void nine_point_average(int h, int w, int i, int j, float in[h][w], float out[h][w]) {float m[NROWS][VLEN]; m[:][:] = in[i:NROWS][j:VLEN]; m[:][:] += in[i+1:NROWS][j:VLEN]; m[:][:] += in[i+2:NROWS][j:VLEN]; m[:][:] += in[i:NROWS][j+1:VLEN]; m[:][:] += in[i+1:NROWS][j+1:VLEN]; m[:][:] += in[i+2:NROWS][j+1:VLEN]; m[:][:] += in[i:NROWS][j+2:VLEN]; m[:][:] += in[i+1:NROWS][j+2:VLEN]; m[:][:] += in[i+2:NROWS][j+2:VLEN]; out[i:NROWS][j:VLEN] = 0.1111f * m[:][:]; } //--------------------------------------------------------------------- // caller //--------------------------------------------------------------------- const int width = 512; const int height = 512; typedef float (*p2d)[]; int main() {p2d src = (p2d) malloc(width*height*sizeof(float)); p2d dst = (p2d) malloc(width*height*sizeof(float)); // … // perform average over 9 points cilk_for (int i = 0; i < height - NROWS - 3; i += NROWS) { for (int j = 0; j < width - VLEN - 3; j += VLEN) {nine_point_average(height, width, i, j, src, dst); } } } |
| Command-line entry |
icl -Qstd=c99 test.c |
Multi-Dimensional Casting Operations
For arrays of two or more dimensions the C language uses row-major ordering. When porting code to array notation format, it is not uncommon to encounter array access patterns that are impossible to express using array notations. However, you can often convert the array into a form that is suitable.
For instance, consider that you want to access the data in the center of a 4x4 array.
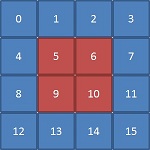
This 4x4 array can be represented as a two-dimensional array as follows:

If you are porting code in which this 2-dimensional data is represented as a 1-dimensional array there is no way to express this access pattern using array notation alone, unless you convert your array into a 2-dimensional one. You can do this as follows:
float (*array_2D)[4] = (float (*)[4])array_1D;
Using this method, the above access pattern can be made accessible as array notations as follows:
array_2D[1:2][1:2];
You can extend this approach to any dimensionality, as the following example illustrates.
| Example |
|---|
#define XRES 48 #define YRES 64 #define ZRES 48 float (*array_3D)[YRES][XRES] = (float (*)[YRES][XRES])array_1D; array_3D[1:ZRES-2][1:YRES-2][1:XRES-2]; |